- May 5
JERK Report #12: Who owns what you write with AI?
I'm not a lawyer. This is signal commentary on a fast-moving legal landscape, not legal advice. Terms cited reflect publicly available documents as of May 2026 and may have changed. Run any decisions past your own counsel before acting.
Today's report is structured a little differently. The four signals — position, velocity, acceleration, jerk — come further down than usual. The setup matters. Keep reading.
This week's note started with me wondering whether what I publish in the JERK Report is copyrightable. Do I own that IP?
I thought the question was whether AI companies are claiming rights to what we create with their tools.
It's more nuanced than that.
Last week the question was who is using AI. This week the question is who owns what comes out the other side.
And it matters to you and your business — because the rules aren't where most people think they are. They're changing fast. If you use AI for your own work, your team's work, or your clients' work, the contract you signed governs what you can do, what gets kept, and what gets used. Most people haven't read it.
AI ownership isn't one question. It's six.
Each platform answers them differently.
Fragmentation
In the late 1990s, Esther Dyson saw this coming. She wrote that copyright was about to come apart. The bundle of rights that copyright law had treated as one thing — ownership, control, attribution, payment — was going to fragment under digital conditions.
Each question would have to be answered on its own.
Each would have its own contract.
She was right.
In 2013, Jaron Lanier saw the next move and wrote about it in Who Owns the Future? He pointed out that Instagram, when Facebook bought it for a billion dollars, had thirteen employees. Kodak at its peak had a hundred and forty thousand. Both companies were worth roughly the same.
Lanier's point wasn't that the Instagram people were extraordinary. It was that Instagram captured the value of millions of users' photos, taste, and attention without paying any of them. Kodak paid lab techs, sales staff, equipment makers, photographers. Instagram paid thirteen people.
The middle disappeared.
He called the pattern siren servers — platforms that aggregate value from many contributors without paying them, then concentrate the upside.
What's happening with AI is the same pattern Dyson described, working through the mechanism Lanier named.
The copyright bundle is fragmenting again.
What Dyson predicted as four questions has become six.
The four old ones: ownership, control, credit, payment.
Two new ones: training, discovery.
Can your conversation train the next model? Can your conversation be pulled into someone else's court case? Those are the two questions copyright law never had to answer before.

Where these six answers live
The answers aren't in one document. They're spread across many. Each updates on its own schedule. Some are specific to your business tier. The answers vary by platform.
Terms of Use. The consumer agreement. Varies by tier — free, paid, pro. Covers ownership, training defaults, dispute handling.
Privacy Policy. What's collected. How long it's kept. Who it's shared with.
Services Agreement. The business contract. ChatGPT Business, Enterprise, Education, Healthcare, and API (the developer interface for building with AI) usage on the OpenAI side — Anthropic, Google, and Microsoft have their own equivalents. Different ownership terms, training defaults, and protections. If you use AI for client work, this is the document that applies to you — not the one you clicked through to sign up.
Service Terms. The addendum. Feature-specific rules — voice, custom GPTs, Codex — and industry-specific ones for education and healthcare.
Which tier are you on?
Consumer tiers are anything you signed up for as an individual — free accounts, ChatGPT Plus, ChatGPT Pro, Claude Pro, Gemini Advanced, Perplexity Pro. You paid with a personal credit card. You clicked through Terms of Use.
Business and enterprise tiers are anything you sign up for through a company — ChatGPT Team, ChatGPT Business, ChatGPT Enterprise, Claude Team, Claude Enterprise, Gemini for Workspace, Microsoft 365 Copilot at the business level. The company signed a Services Agreement. There's a billing relationship and a contract behind it.
The line matters because the contracts are different. Training defaults are different. Privacy commitments are different. Some include protection if a model output infringes someone else's copyright. The cost difference is small. The contract difference is large.
Note on agent tools and coding tools
They don't run on consumer terms.
Tools like Claude Code, Claude Cowork, ChatGPT Codex, ChatGPT Operator, Google Gemini Agent Mode, and Microsoft Copilot Studio run on business-tier agreements — Anthropic Commercial Terms, OpenAI Services Agreement, Google Cloud Terms, Microsoft Customer Agreement.
Vibe-coding tools — Cursor, Lovable, Bolt, v0, Replit Agent, Windsurf — usually run on top of the major LLM APIs. The API agreement is what governs you.
If you use any of these for client work, the business-tier or API agreement is the one that matters.
As of May 2026, those are the documents. They update separately. Most users have read one at most.
Where each platform actually stands
For content you generate with an AI tool — a paragraph, an image, a code snippet — here's where the major platforms stand on each of the six questions, as of May 2026.
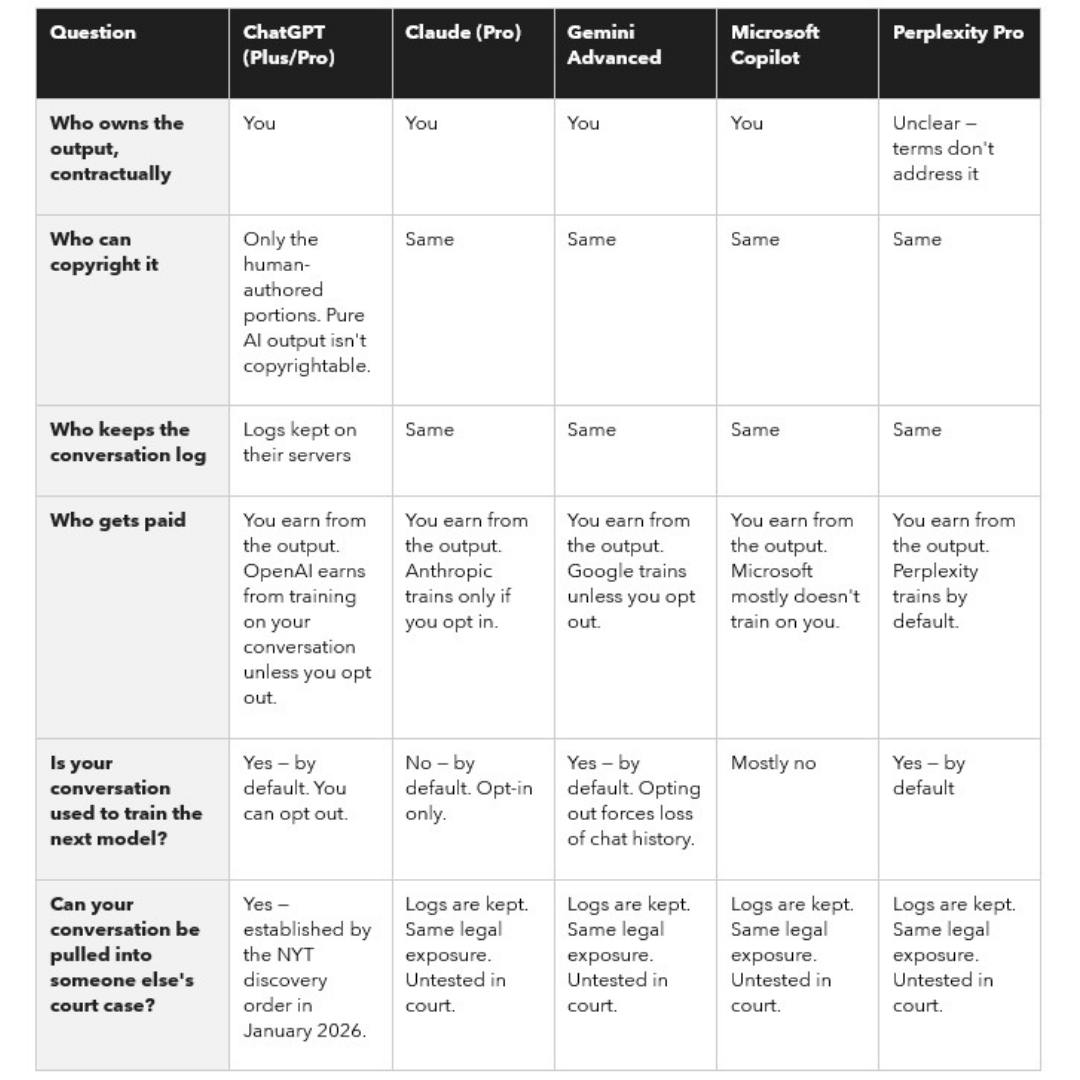
The last row is the one to read carefully.
The court's reasoning applied to OpenAI because OpenAI was the defendant.
The reasoning travels.
Every platform that keeps logs is now planning for the same precedent.
The NYT v. OpenAI discovery order set the template. The court found that users voluntarily submitted their communications to a platform that legally owns the logs. That logic applies to every AI conversation anyone has ever had on a platform that keeps logs.
Reading the derivatives

Position. What's true today.
You can use what you make with AI. Whether you legally own it depends on how much of you is in it.
The U.S. Copyright Office published guidance in January 2025 on what counts. The short version: copyright protects human creative expression, not machine output. A prompt isn't enough — even a long, detailed one. Light editing isn't enough.
What does qualify:
• Substantial human modification of the AI output.
• Creative selection and arrangement of AI-generated material.
• AI used as a tool inside a larger work that's clearly your own creation.
• Expressive inputs — your own writing, images, or recordings used as the basis for the AI to work on.
The test isn't whether you used AI. It's whether the human creative judgment in the final work is clearly perceptible and separable from what the machine produced. Case by case. The more of you that's in it, the more of it is yours.
Velocity. What's changing.
Training defaults are diverging across platforms. Anthropic moved to opt-in for consumers in August 2025. ChatGPT Plus, Gemini Advanced, and Perplexity Pro still train on your conversations by default.
Whether your data trains the next model depends entirely on which tier you're on. Consumer paid tiers train by default. Business and enterprise tiers don't.
Acceleration. The change is itself speeding up.
Three Anthropic suits resolved or in motion in three months — a $1.5B settlement with authors covering past use, a $3.1B claim from music publishers, a $70M follow-on suit.
The Microsoft–OpenAI partnership got rewritten two weeks ago. Exclusivity gone. The artificial general intelligence (AGI) clause removed. GPT-5.4 moved from Microsoft cloud to AWS Bedrock the next morning.
Each settlement makes the next suit easier to file. Each contract revision pressures the next, and strips the benefits to smaller players.
Jerk. What's shifting underneath.
On January 5, 2026, a federal judge ordered OpenAI to produce 20 million ChatGPT conversation logs in the New York Times copyright case. Anonymized. From consumer accounts. December 2022 through November 2024.
OpenAI argued this would invade user privacy. The court disagreed.
The reasoning matters. ChatGPT users, the court said, voluntarily submitted their communications. OpenAI legally owns the logs. Users have a real privacy interest, but it's protected enough by anonymization and a protective order.
For your business, this means the rules governing your AI use are being written in three different rooms at once — and the rooms are now talking to each other. A contract change can come from a court ruling. A retention policy can come from a settlement. A discovery exposure can come from a competitor's lawsuit you've never heard of.
That's the jerk.
Not the ruling. The coupling.
Copyright law, contract terms, and discovery rules used to operate in separate lanes. They're now actively reshaping each other. A copyright suit produces a discovery order. The discovery order changes how every platform writes its retention policy. The retention policy changes what's discoverable in the next suit.
Three legal domains, locked together, accelerating.
The ruling is the evidence.
The coupling is the jerk.
The legal architecture for AI-assisted work is being written this year, by litigation, in courts most users have never heard of.
What should have more public discourse does not.
Your five-minute practice this week
Open the data controls in whatever tool you use. Turn off training.
That's the five minutes.
If you wouldn't want a specific conversation appearing in someone else's court case five years from now, don't have it on a consumer tier. This is typically governed by your Terms of Use and the Privacy Policy.
The other two moves below are this month's work, not this week's.
This month — move client work off the consumer tier
If you run a business that uses AI, move anyone putting client work or IP into the LLM off the consumer tier. Client data. Internal strategy. Vendor information. Financials. Customer lists. Half of what you put into AI in a typical week would be a problem if it surfaced somewhere it shouldn't.
If you're on a consumer tier, you're using a contract written for personal use. The training defaults, privacy commitments, and protections are different.
Business and enterprise tiers — ChatGPT Business and Enterprise, Claude Team, Gemini for Workspace — don't train on your data by default. They have stronger privacy commitments. Some include protection if a model output infringes someone else's copyright.
The cost difference is small. The contract difference is large.
This is typically governed by the Services Agreement, not the Terms of Use you clicked through.
This month — audit which workflows touch which data
For anything that involves client confidentiality, IP, or material you'd be uncomfortable seeing in someone else's lawsuit — confirm the retention setting, not just the training setting. They're different.
For Custom GPTs, API calls, agent workflows, and vibe-coding with client data or proprietary IP, the conversation log itself is also a risk. Logs you generate today can be pulled into someone else's court case. Anonymization is the protection. The protection is partial.
Zero Data Retention is available on the API tier for an additional commitment. It eliminates the 30-day default retention window. If you're handling sensitive client work at volume, this is the column to check.
This is typically governed by the Services Agreement and the Data Processing Addendum.
A live test of the framework
I started this week's report by asking whether what I publish in the JERK Report is copyrightable.
The answer turned out to be yes — but only because I write the way I write. In my voice. With synthesis across odd domains. My own framework. The way I arrange a passage is mine.
The answer would not have been yes if I'd been generating output and lightly editing it.
The more of you that's in it, the more of it is yours.
On a call this morning I said OpenAI claims the right to your work when you create it with ChatGPT.
That's wrong.
OpenAI's terms assign output rights to the user. So does Anthropic. So does Google. So does Microsoft. The contractual answer to "who owns the output" is you — across every major platform.
I'd been reading pieces of this story for months. The training lawsuits. The discovery orders. The newsletters with sharper headlines than the underlying facts. Each piece confirmed something I already half-believed. My confirmation bias felt like understanding — until I caught myself pausing before I said it out loud, and realized I needed to dig in.
And when you're sure about something fast-moving, pause before you say it out loud.
This is a fast-moving topic in a short newsletter. All of it will keep changing. I'll keep watching. You should too.
I'm not a lawyer. This is signal commentary on a fast-moving legal landscape, not legal advice. Terms cited reflect publicly available documents as of May 2026 and may have changed. Run any decisions past your own counsel before acting.
This is JERK Report Issue #12.
Check out the Jerk Report,
The JERK Report is a weekly signal read for small business owners. One signal. Four layers. A five-minute practice. Every Monday. From Rose Thun at Design Rosetta